The Mixture of Experts (MoE) architecture has emerged as a promising approach for scaling up Large Language Models (LLMs), facilitating more efficient training and inference. Regarding this potential, our work extends the MoE architecture to develop Uni-MoE, a unified Multimodal LLM designed to process a wide array of modalities, including audio, speech, images, text, and video. Specifically, our methodology enriches the transformer architecture of LLMs by incorporating multimodal experts, comprising: 1). a shared self-attention mechanism for all modalities, 2). modality-specific experts derived from feed-forward networks, and 3). a sparse routing mechanism for allocating token-level expert attention. We evaluate our instruction-tuned, MoE-based MLLM on a comprehensive set of multimodal datasets. The results underscore Uni-MoE's three principal benefits: a). superior performance compared to existing dense multimodal models with single-expert configurations across various benchmarks; b). enhanced multi-expert collaboration and generalization through the pre-training of modality-specific experts, rather than applying a generic MoE model directly to heterogeneous data; c). exceptional ability in handling complex cross-modality tasks such as the High School English Listening Test and Video Comprehension, demonstrating effective complexity management and reduced bias in handling mixed multimodal datasets. Our findings suggest the significant potential of MoE frameworks in the advancement of MLLMs and encourage further research in this domain. The code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
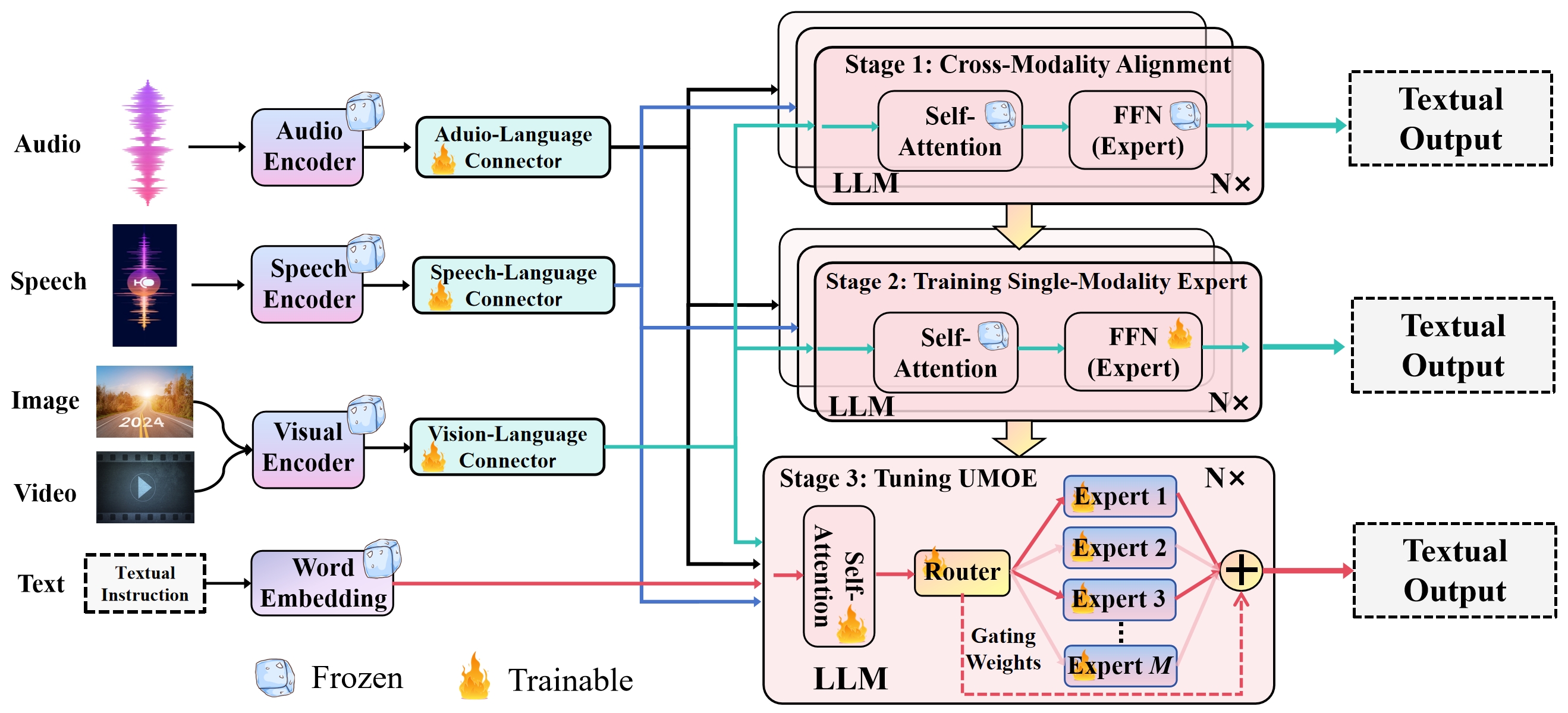
Figure 1:Architecture of Uni-MoE. By connecting LLM with multimodal encoders, Uni-MoE shows unified multimodal understanding capability. It mainly employs the MoE architecture to achieve stable and powerful performance on any multi-modal information input.
@misc{li2024unimoe,
title={Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts},
author={Yunxin Li and Shenyuan Jiang and Baotian Hu and Longyue Wang and Wanqi Zhong and Wenhan Luo and Lin Ma and Min Zhang},
year={2024},
eprint={2405.11273},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. We thank the LLaMA team for giving us access to their models, and open-source projects, including Vicuna, BEATs and whisper.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of CLIP, BEATs, whisper, LLaMA and Vicuna. The dataset and models trained using the dataset should not be used outside of research purposes.


